Common Processor Architectures
-
Harvard
- optimized for parallel fetches: separate program & data memories
- both memories can be accessed simultaneously → higher throughput
- typically in simple/specialized cores (DSPs, microcontrollers)
-
von Neumann
- unified program + data memory (“stored-program”)
- simpler silicon, more flexible instruction set
- shared bus creates the “von Neumann bottleneck” → limits throughput
- used in general-purpose CPUs
- When to use which?
- Harvard → real-time, low-latency embedded
- von Neumann → complex OS, rich ISA
Integrated Circuit Cost
- Cost per die
- Dies per wafer ≈
- Yield = fraction of good dies after fabrication defects
CPU Performance Metrics
-
Clock rate vs. cycle time
-
CPU execution time
- via cycles × time:
- via rate:
-
Breaking down Clock cycles
-
Unified CPU time formula
Performance Trade-offs
- Reduce Instruction count
– better algorithms, more powerful ISA - Reduce CPI
– deeper pipelines, more parallelism - Increase Clock rate
– faster transistors, shorter cycle time - Trade-off example: deeper pipelines → higher clock rate but can increase CPI on mispredictions
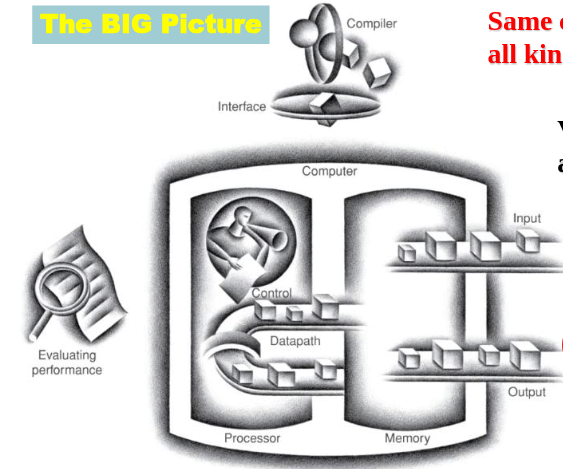
Big Picture & Amdahl’s Law
- Overall speedup when improving a feature that accelerates fraction of computation by factor :
- shows diminishing returns as